Image from @awsgeek
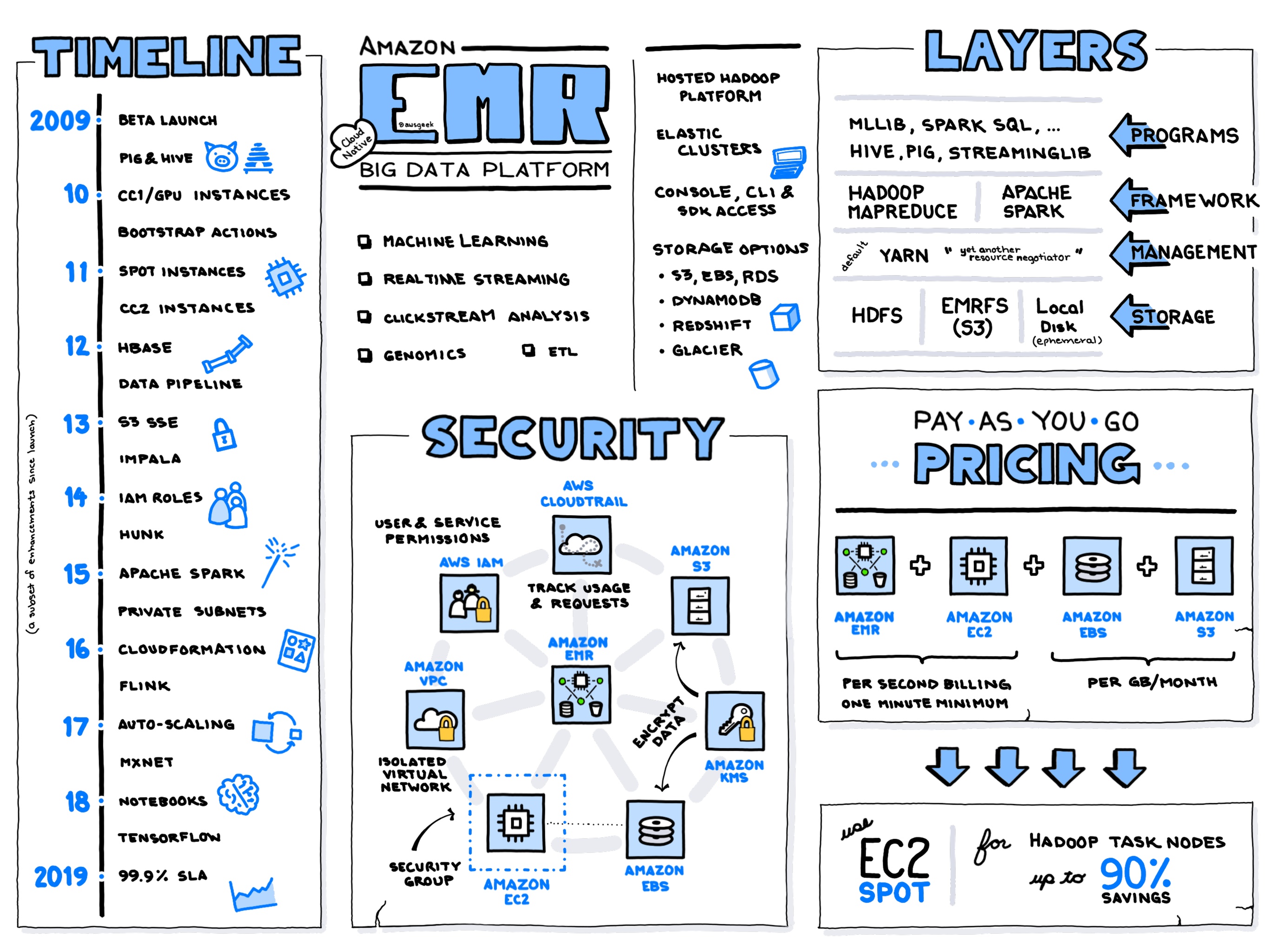
Elastic MapReduce
EMR Basics
- 📒 Homepage ∙ Release guide ∙ FAQ ∙ Pricing
- EMR (which used to stand for Elastic Map Reduce, but not anymore, since it now extends beyond map-reduce) is a service that offers managed deployment of Hadoop, HBase and Spark. It reduces the management burden of setting up and maintaining these services yourself.
EMR Alternatives and Lock-in
- ⛓Most of EMR is based on open source technology that you can in principle deploy yourself. However, the job workflows and much other tooling is AWS-specific. Migrating from EMR to your own clusters is possible but not always trivial.
EMR Tips
- EMR relies on many versions of Hadoop and other supporting software. Be sure to check which versions are in use.
- ⏱Off-the-shelf EMR and Hadoop can have significant overhead when compared with efficient processing on a single machine. If your data is small and performance matters, you may wish to consider alternatives, as this post illustrates.
- Python programmers may want to take a look at Yelp’s mrjob.
- It takes time to tune performance of EMR jobs, which is why third-party services such as Qubole’s data service are gaining popularity as ways to improve performance or reduce costs.
EMR Gotchas and Limitations
- 💸❗EMR costs can pile up quickly since it involves lots of instances, efficiency can be poor depending on cluster configuration and choice of workload, and accidents like hung jobs are costly. See the section on EC2 cost management, especially the tips there about Spot instances. This blog post has additional tips, but was written prior to the shift to per-second billing.
- 💸 Beware of “double-dipping”. With EMR, you pay for the EC2 capacity and the service fees. In addition, EMR syncs task logs to S3, which means you pay for the storage and PUT requests at S3 standard rates. While the log files tend to be relatively small, every Hadoop job, depending on the size, generates thousands of log files that can quickly add up to thousands of dollars on the AWS bill. YARN’s log aggregation is not available on EMR.