Image from @awsgeek
Simple Storage Service
S3 Basics
- 📒 Homepage ∙ Developer guide ∙ FAQ ∙ Pricing
- S3 (Simple Storage Service) is AWS’ standard cloud storage service, offering file (opaque “blob”) storage of arbitrary numbers of files of almost any size, from 0 to 5TB. (Prior to 2011 the maximum size was 5 GB; larger sizes are now well supported via multipart support.)
- Items, or objects, are placed into named buckets stored with names which are usually called keys. The main content is the value.
- Objects are created, deleted, or updated. Large objects can be streamed, but you cannot modify parts of a value; you need to update the whole object. Partial data access can work via S3 Select.
- Every object also has metadata, which includes arbitrary key-value pairs, and is used in a way similar to HTTP headers. Some metadata is system-defined, some are significant when serving HTTP content from buckets or CloudFront, and you can also define arbitrary metadata for your own use.
- S3 URIs: Although often bucket and key names are provided in APIs individually, it’s also common practice to write an S3 location in the form 's3://bucket-name/path/to/key' (where the key here is 'path/to/key'). (You’ll also see 's3n://' and 's3a://' prefixes in Hadoop systems.)
- S3 vs Glacier, EBS, and EFS: AWS offers many storage services, and several besides S3 offer file-type abstractions. Glacier is for cheaper and infrequently accessed archival storage. EBS, unlike S3, allows random access to file contents via a traditional filesystem, but can only be attached to one EC2 instance at a time. EFS is a network filesystem many instances can connect to, but at higher cost. See the comparison table.
S3 Tips
- For most practical purposes, you can consider S3 capacity unlimited, both in total size of files and number of objects. The number of objects in a bucket is essentially also unlimited. Customers routinely have millions of objects.
- ❗Permissions:
- 🔸If you're storing business data on Amazon S3, it’s important to manage permissions sensibly. In 2017 companies like Dow Jones and Verizon saw data breaches due to poorly-chosen S3 configuration for sensitive data. Fixing this later can be a difficult task if you have a lot of assets and internal users.
- 🔸There are 3 different ways to grant permissions to access Amazon S3 content in your buckets.
- IAM policies use the familiar Identity and Authentication Management permission scheme to control access to specific operations.
- Bucket policies grant or deny permissions to an entire bucket. You might use this when hosting a website in S3, to make the bucket publicly readable, or to restrict access to a bucket by IP address. Amazon's sample bucket policies show a number of use cases where these policies come in handy.
- Access Control Lists (ACLs) can also be applied to every bucket and object stored in S3. ACLs grant additional permissions beyond those specified in IAM or bucket policies. ACLs can be used to grant access to another AWS user, or to predefined groups like the general public. This is powerful but can be dangerous, because you need to inspect every object to see who has access.
- 🔸AWS' predefined access control groups allow access that may not be what you'd expect from their names:
- "All Users", or "Everyone", grants permission to the general public, not only to users defined in your own AWS account. If an object is available to All Users, then it can be retrieved with a simple HTTP request of the form
http://s3.amazonaws.com/bucket-name/filename. No authorization or signature is required to access data in this category. - "Authenticated Users" grants permissions to anyone with an AWS account, again not limited to your own users. Because anyone can sign up for AWS, for all intents and purposes this is also open to the general public.
- "Log Delivery" group is used by AWS to write logs to buckets and should be safe to enable on the buckets that need it.
- A typical use case of this ACL is used in conjunction with the requester pays functionality of S3.
- "All Users", or "Everyone", grants permission to the general public, not only to users defined in your own AWS account. If an object is available to All Users, then it can be retrieved with a simple HTTP request of the form
- ❗ Bucket permissions and object permissions are two different things and independent of each other. A private object in a public bucket can be seen when listing the bucket, but not downloaded. At the same time, a public object in a private bucket won't be seen because the bucket contents can't be listed, but can still be downloaded by anyone who knows its exact key. Users that don't have access to set bucket permissions can still make objects public if they have
s3:PutObjectAclors3:PutObjectVersionAclpermissions. - 🐥In August 2017, AWS added AWS Config rules to ensure your S3 buckets are secure.
- ❗These AWS Config rules only check the security of your bucket policy and bucket-level ACLs. You can still create object ACLs that grant additional permissions, including opening files to the whole world.
- 🔹Do create new buckets if you have different types of data with different sensitivity levels. This is much less error prone than complex permissions rules. For example, if data is for administrators only, like log data, put it in a new bucket that only administrators can access.
- For more guidance, see:
- Bucket naming: Buckets are chosen from a global namespace (across all regions, even though S3 itself stores data in whichever S3 region you select), so you’ll find many bucket names are already taken. Creating a bucket means taking ownership of the name until you delete it. Bucket names have a few restrictions on them.
- Bucket names can be used as part of the hostname when accessing the bucket or its contents, like
<bucket_name>.s3-us-east-1.amazonaws.com, as long as the name is DNS compliant. - A common practice is to use the company name acronym or abbreviation to prefix (or suffix, if you prefer DNS-style hierarchy) all bucket names (but please, don’t use a check on this as a security measure — this is highly insecure and easily circumvented!).
- 🔸Bucket names with '.' (periods) in them can cause certificate mismatches when used with SSL. Use '-' instead, since this then conforms with both SSL expectations and is DNS compliant.
- Bucket names can be used as part of the hostname when accessing the bucket or its contents, like
- Versioning: S3 has optional versioning support, so that all versions of objects are preserved on a bucket. This is mostly useful if you want an archive of changes or the ability to back out mistakes (caution: it lacks the featureset of full version control systems like Git).
- Durability: Durability of S3 is extremely high, since internally it keeps several replicas. If you don’t delete it by accident, you can count on S3 not losing your data. (AWS offers the seemingly improbable durability rate of 99.999999999%, but this is a mathematical calculation based on independent failure rates and levels of replication — not a true probability estimate. Either way, S3 has had a very good record of durability.) Note this is much higher durability than EBS!
- 💸S3 pricing depends on storage, requests, and transfer.
- For transfer, putting data into AWS is free, but you’ll pay on the way out. Transfer from S3 to EC2 in the same region is free. Transfer to other regions or the Internet in general is not free.
- Deletes are free.
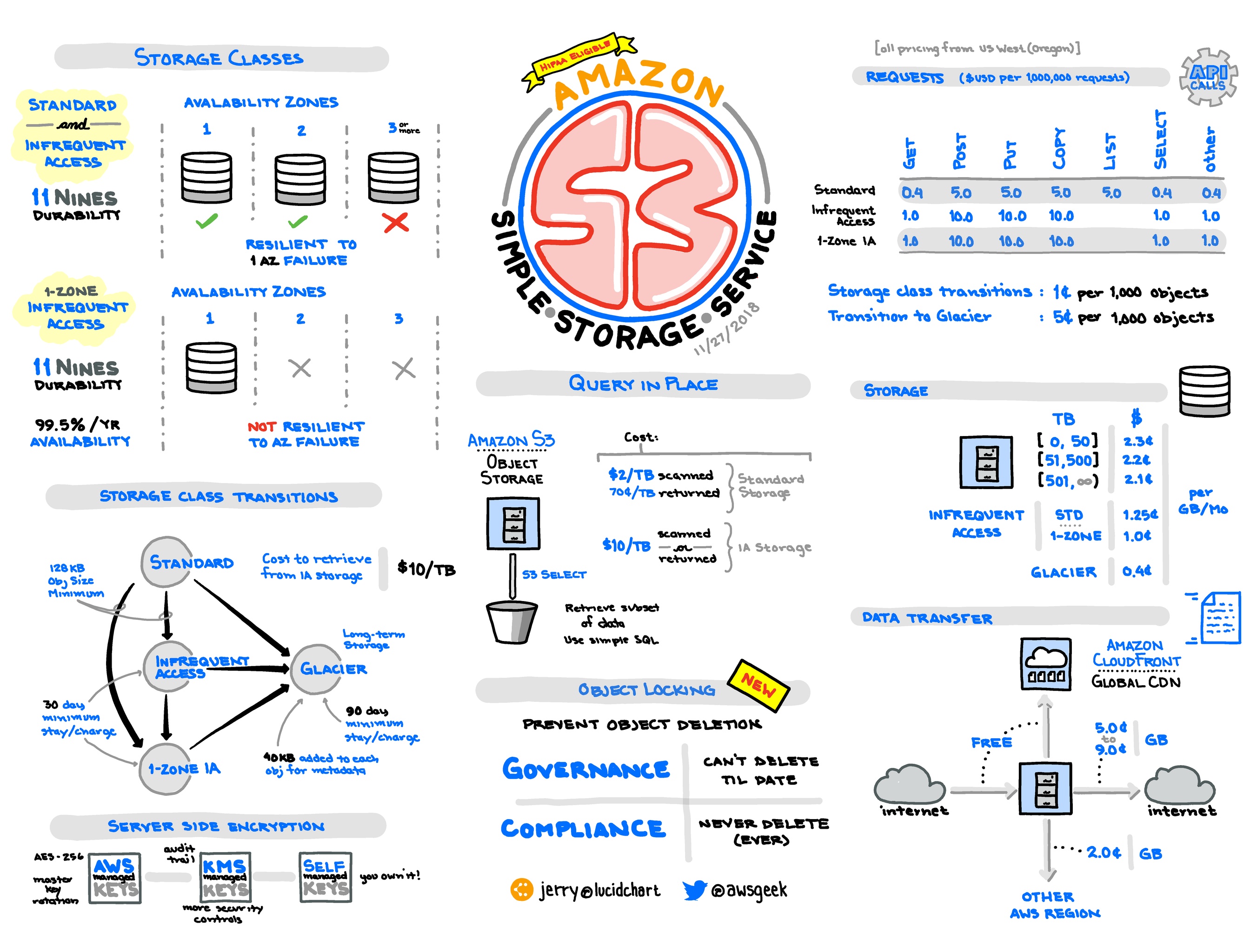
- S3 Reduced Redundancy and Infrequent Access: Most people use the Standard storage class in S3, but there are other storage classes with lower cost:
- 🔸Reduced Redundancy Storage (RRS) has been effectively deprecated, and has lower durability (99.99%, so just four nines) than standard S3. Note that it no longer participates in S3 price reductions, so it offers worse redundancy for more money than standard S3. As a result, there's no reason to use it.
- Infrequent Access (IA) lets you get cheaper storage in exchange for more expensive access. This is great for archives like logs you already processed, but might want to look at later. To get an idea of the cost savings when using Infrequent Access (IA), you can use this S3 Infrequent Access Calculator.
- S3 - Intelligent Tiering storage class is designed to optimize costs by automatically moving data to the most cost-effective access tier, without performance impact or operational overhead.
- S3 - One Zone - IA is for data that is accessed less frequently, but requires rapid access when needed. Unlike other S3 Storage Classes which store data in a minimum of three Availability Zones (AZs), S3 One Zone-IA stores data in a single AZ and costs 20% less than S3 Standard-IA.
- Glacier is a third alternative discussed as a separate product.
- See the comparison table.
- ⏱Performance: Maximizing S3 performance means improving overall throughput in terms of bandwidth and number of operations per second.
- S3 is highly scalable, so in principle you can get arbitrarily high throughput. (A good example of this is S3DistCp.)
- But usually you are constrained by the pipe between the source and S3 and/or the level of concurrency of operations.
- Throughput is of course highest from within AWS to S3, and between EC2 instances and S3 buckets that are in the same region.
- Bandwidth from EC2 depends on instance type. See the “Network Performance” column at ec2instances.info.
- Throughput of many objects is extremely high when data is accessed in a distributed way, from many EC2 instances. It’s possible to read or write objects from S3 from hundreds or thousands of instances at once.
- However, throughput is very limited when objects accessed sequentially from a single instance. Individual operations take many milliseconds, and bandwidth to and from instances is limited.
- Therefore, to perform large numbers of operations, it’s necessary to use multiple worker threads and connections on individual instances, and for larger jobs, multiple EC2 instances as well.
- Multi-part uploads: For large objects you want to take advantage of the multi-part uploading capabilities (starting with minimum chunk sizes of 5 MB).
- Large downloads: Also you can download chunks of a single large object in parallel by exploiting the HTTP GET range-header capability.
- 🔸List pagination: Listing contents happens at 1000 responses per request, so for buckets with many millions of objects listings will take time.
- ❗Key prefixes: Previously randomness in the beginning of key names was necessary in order to avoid hot spots, but that is no longer necessary as of July, 2018.
- For data outside AWS, DirectConnect and S3 Transfer Acceleration can help. For S3 Transfer Acceleration, you pay about the equivalent of 1-2 months of storage for the transfer in either direction for using nearer endpoints.
- Command-line applications: There are a few ways to use S3 from the command line:
- Originally, s3cmd was the best tool for the job. It’s still used heavily by many.
- The regular aws command-line interface now supports S3 well, and is useful for most situations.
- s4cmd is a replacement, with greater emphasis on performance via multi-threading, which is helpful for large files and large sets of files, and also offers Unix-like globbing support.
- GUI applications: You may prefer a GUI, or wish to support GUI access for less technical users. Some options:
- The AWS Console does offer a graphical way to use S3. Use caution telling non-technical people to use it, however, since without tight permissions, it offers access to many other AWS features.
- Transmit is a good option on macOS for most use cases.
- Cyberduck is a good option on macOS and Windows with support for multipart uploads, ACLs, versioning, lifecycle configuration, storage classes and server side encryption (SSE-S3 and SSE-KMS).
- S3 and CloudFront: S3 is tightly integrated with the CloudFront CDN. See the CloudFront section for more information, as well as S3 transfer acceleration.
- Static website hosting:
- S3 has a static website hosting option that is simply a setting that enables configurable HTTP index and error pages and HTTP redirect support to public content in S3. It’s a simple way to host static assets or a fully static website.
- Consider using CloudFront in front of most or all assets:
- Like any CDN, CloudFront improves performance significantly.
- 🔸SSL is only supported on the built-in amazonaws.com domain for S3. S3 supports serving these sites through a custom domain, but not over SSL on a custom domain. However, CloudFront allows you to serve a custom domain over https. Amazon provides free SNI SSL/TLS certificates via Amazon Certificate Manager. SNI does not work on very outdated browsers/operating systems. Alternatively, you can provide your own certificate to use on CloudFront to support all browsers/operating systems for a fee.
- 🔸If you are including resources across domains, such as fonts inside CSS files, you may need to configure CORS for the bucket serving those resources.
- Since pretty much everything is moving to SSL nowadays, and you likely want control over the domain, you probably want to set up CloudFront with your own certificate in front of S3 (and to ignore the AWS example on this as it is non-SSL only).
- That said, if you do, you’ll need to think through invalidation or updates on CloudFront. You may wish to include versions or hashes in filenames so invalidation is not necessary.
- Data lifecycles:
- When managing data, the understanding the lifecycle of the data is as important as understanding the data itself. When putting data into a bucket, think about its lifecycle — its end of life, not just its beginning.
- 🔹In general, data with different expiration policies should be stored under separate prefixes at the top level. For example, some voluminous logs might need to be deleted automatically monthly, while other data is critical and should never be deleted. Having the former in a separate bucket or at least a separate folder is wise.
- 🔸Thinking about this up front will save you pain. It’s very hard to clean up large collections of files created by many engineers with varying lifecycles and no coherent organization.
- Alternatively you can set a lifecycle policy to archive old data to Glacier. Be careful with archiving large numbers of small objects to Glacier, since it may actually cost more.
- There is also a storage class called Infrequent Access that has the same durability as Standard S3, but is discounted per GB. It is suitable for objects that are infrequently accessed.
- Data consistency: Understanding data consistency is critical for any use of S3 where there are multiple producers and consumers of data.
- Creation and updates to individual objects in S3 are atomic, in that you’ll never upload a new object or change an object and have another client see only part half the change.
- The uncertainty lies with when your clients and other clients see updates.
- New objects: If you create a new object, you’ll be able to read it instantly, which is called read-after-write consistency.
- Well, with the additional caveat that if you do a read on an object before it exists, then create it, you get eventual consistency (not read-after-write).
- This does not apply to any list operations; newly created objects are not guaranteed to appear in a list operation right away
- Updates to objects: If you overwrite or delete an object, you’re only guaranteed eventual consistency, i.e. the change will happen but you have no guarantee of when.
- 🔹For many use cases, treating S3 objects as immutable (i.e. deciding by convention they will be created or deleted but not updated) can greatly simplify the code that uses them, avoiding complex state management.
- 🔹Note that until 2015, 'us-standard' region had had a weaker eventual consistency model, and the other (newer) regions were read-after-write. This was finally corrected — but watch for many old blogs mentioning this!
- Slow updates: In practice, “eventual consistency” usually means within seconds, but expect rare cases of minutes or hours.
- S3 as a filesystem:
- In general S3’s APIs have inherent limitations that make S3 hard to use directly as a POSIX-style filesystem while still preserving S3’s own object format. For example, appending to a file requires rewriting, which cripples performance, and atomic rename of directories, mutual exclusion on opening files, and hardlinks are impossible.
- s3fs is a FUSE filesystem that goes ahead and tries anyway, but it has performance limitations and surprises for these reasons.
- Riofs (C) and Goofys (Go) are more recent efforts that attempt adopt a different data storage format to address those issues, and so are likely improvements on s3fs.
- S3QL (discussion) is a Python implementation that offers data de-duplication, snap-shotting, and encryption, but only one client at a time.
- ObjectiveFS (discussion) is a commercial solution that supports filesystem features and concurrent clients.
- If you are primarily using a VPC, consider setting up a VPC Endpoint for S3 in order to allow your VPC-hosted resources to easily access it without the need for extra network configuration or hops.
- Cross-region replication: S3 has a feature for replicating a bucket between one region and another. Note that S3 is already highly replicated within one region, so usually this isn’t necessary for durability, but it could be useful for compliance (geographically distributed data storage), lower latency, or as a strategy to reduce region-to-region bandwidth costs by mirroring heavily used data in a second region.
- IPv4 vs IPv6: For a long time S3 only supported IPv4 at the default endpoint
https://BUCKET.s3.amazonaws.com. However, as of Aug 11, 2016 it now supports both IPv4 & IPv6! To use both, you have to enable dualstack either in your preferred API client or by directly using this url schemehttps://BUCKET.s3.dualstack.REGION.amazonaws.com. This extends to S3 Transfer Acceleration as well. - S3 event notifications: S3 can be configured to send an SNS notification, SQS message, or AWS Lambda function on bucket events.
- 💸Limit your individual users (or IAM roles) to the minimal required S3 locations, and catalog the “approved” locations. Otherwise, S3 tends to become the dumping ground where people put data to random locations that are not cleaned up for years, costing you big bucks.
- If a bucket is deleted in S3, it can take up to 10 hours before a bucket with the same name can be created again. (discussion)
S3 Gotchas and Limitations
- ❗S3 buckets sit outside the VPC and can be accessed from anywhere in the world if bucket policies are not set to deny it. Read the permissions section above carefully, there are countless cases of buckets exposed to the public.
- 🔸For many years, there was a notorious 100-bucket limit per account, which could not be raised and caused many companies significant pain. As of 2015, you can request increases. You can ask to increase the limit, but it will still be capped (generally below ~1000 per account).
- 🔸Be careful not to make implicit assumptions about transactionality or sequencing of updates to objects. Never assume that if you modify a sequence of objects, the clients will see the same modifications in the same sequence, or if you upload a whole bunch of files, that they will all appear at once to all clients.
- 🔸S3 has an SLA with 99.9% uptime. If you use S3 heavily, you’ll inevitably see occasional error accessing or storing data as disks or other infrastructure fail. Availability is usually restored in seconds or minutes. Although availability is not extremely high, as mentioned above, durability is excellent.
- 🔸After uploading, any change that you make to the object causes a full rewrite of the object, so avoid appending-like behavior with regular files.
- 🔸Eventual data consistency, as discussed above, can be surprising sometimes. If S3 suffers from internal replication issues, an object may be visible from a subset of the machines, depending on which S3 endpoint they hit. Those usually resolve within seconds; however, we’ve seen isolated cases when the issue lingered for 20-30 hours.
- 🔸MD5s and multi-part uploads: In S3, the ETag header in S3 is a hash on the object. And in many cases, it is the MD5 hash. However, this is not the case in general when you use multi-part uploads. One workaround is to compute MD5s yourself and put them in a custom header (such as is done by s4cmd).
- 🔸Incomplete multi-part upload costs: Incomplete multi-part uploads accrue storage charges even if the upload fails and no S3 object is created. Amazon (and others) recommend using a lifecycle policy to clean up incomplete uploads and save on storage costs. Note that if you have many of these, it may be worth investigating whatever's failing regularly.
- 🔸US Standard region: Previously, the us-east-1 region (also known as the US Standard region) was replicated across coasts, which led to greater variability of latency. Effective Jun 19, 2015 this is no longer the case. All Amazon S3 regions now support read-after-write consistency. Amazon S3 also renamed the US Standard region to the US East (N. Virginia) region to be consistent with AWS regional naming conventions.
- 🔸S3 authentication versions and regions: In newer regions, S3 only supports the latest authentication. If an S3 file operation using CLI or SDK doesn't work in one region, but works correctly in another region, make sure you are using the latest authentication signature.
Storage Durability, Availability, and Price
As an illustration of comparative features and price, the table below gives S3 Standard, RRS, IA, in comparison with Glacier, EBS, EFS, and EC2 d2.xlarge instance store using Virginia region as of Sept 2017.
| Durability (per year) | Availability “designed” | Availability SLA | Storage (per TB per month) | GET or retrieve (per million) | Write or archive (per million) | |
|---|---|---|---|---|---|---|
| Glacier | Eleven 9s | Sloooow | – | $4 | $50 | $50 |
| S3 IA | Eleven 9s | 99.9% | 99% | $12.50 | $1 | $10 |
| S3 Standard | Eleven 9s | 99.99% | 99.9% | $23 | $0.40 | $5 |
| EBS | 99.8% | Unstated | 99.99% | $25/$45/$100/$125+ (sc1/st1/gp2/io1) | ||
| EFS | “High” | “High” | – | $300 | ||
| EC2 d2.xlarge instance store | Unstated | Unstated | – | $25.44 | $0 | $0 |
Especially notable items are in boldface. Sources: S3 pricing, S3 SLA, S3 FAQ, RRS info (note that this is considered deprecated), Glacier pricing, EBS availability and durability, EBS pricing, EFS pricing, EC2 SLA